Blog
The Real Cost of a Decision: Latency Budgets in Bidding
A bid is a decision made against a stopwatch. Exceed the latency budget and the auction closes without you. Here's where the milliseconds go, why a sub-50ms target shapes the whole architecture, and why in-path ML has to fit inside it.
- Author
- Ad360 engineering
- Discipline
- Platform engineering
Every other consideration in bidding — eligibility, targeting, pacing, the model — assumes one thing that is almost never stated out loud: that the decision arrives in time. A bid is not just a decision; it is a decision made against a stopwatch. The exchange opens an auction, waits a fixed window, and closes it. Miss the window and your bid simply does not exist, no matter how perfect it would have been. Latency is not a performance nicety. It is the boundary inside which all other intelligence must fit.
This is the constraint that quietly shapes a bidder's entire architecture, and the one most "smart bidding" conversations ignore. So let's make it explicit: where do the milliseconds go, what is the budget, and why does it govern everything else?
The budget is real, and it is small
The bidder runs against a sub-50ms target — the time it has to receive a request, decide, and respond before the exchange stops listening. That is the outer wall. In practice, production telemetry shows the system operating well inside it: per-request processing time for requests with ads sits largely in the 1–5ms range, with occasional spikes into the low tens of milliseconds (around ~22ms) clustered at top-of-hour load.
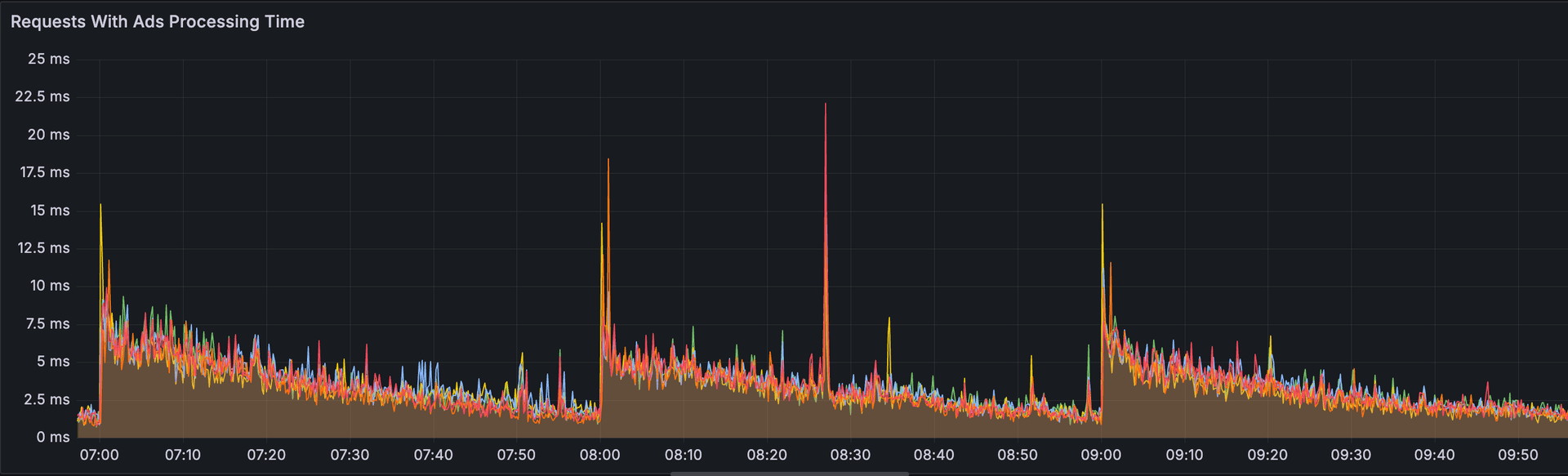
Two things are worth noticing in that profile. First, the typical case is far under the limit — headroom is deliberate, because the budget must hold even under load. Second, the spikes are not random; they cluster when many campaigns refresh at once. A latency budget is not a single number you meet on average. It is a tail you must respect even on your worst-timed millisecond.
Why exceeding it is catastrophic, not costly
In most software, slow is annoying. In bidding, slow is binary. Cross the budget and the exchange times out: the bid never lands, the impression is lost, and from the outside it looks identical to a deliberate no-bid. The damage compounds — timeouts depress win rate and delivery directly, and they do so silently, because a timed-out bid leaves no trace of the good decision it would have been.
This is why latency is the hidden cause behind a class of delivery problems that look like targeting or pacing issues. A campaign can be perfectly configured and still under-deliver because its bids keep arriving a few milliseconds late. The win-rate waterfall shows you which gate loses opportunities; the latency profile tells you whether you're losing them to the clock.
How the budget shapes the funnel
Once you accept the budget as a hard wall, the architecture of the decision follows from it. The decisioning funnel is, in part, an economic ordering of compute against the clock:
- Cheap, decisive filters go first. Eligibility and hard targeting constraints (creative fit, geo, device, floor) are fast to evaluate and eliminate the most candidates. Running them early shrinks the work everything downstream must do.
- Expensive work goes last. Model inference is comparatively costly, so it runs near the end, on the small fraction of opportunities that survived the cheap gates. Scoring an impression the campaign was never eligible to win is pure latency waste.
- In-path ML must fit inside the budget. The model cannot take a leisurely round trip; it has to return a prediction within the same millisecond envelope as everything else. That constraint drives concrete choices — a fast model class (boosted trees), preloaded models, a lean serving protocol (gRPC), horizontal scaling.
In other words, the latency budget is not a property the architecture has; it is the force that produced the architecture. Every stage in the waterfall is also a line item in a time budget.
Latency is an operational concern, not an SLA poster
A subtle point from how this gets treated in practice: latency is often not framed as a formal contractual SLA, and yet it is operationally critical. Degradation hits win rates, spend, and delivery directly, so it is watched and tuned as a live production property — during ramp-ups, under load, as scale grows. The lesson is that the most important performance constraints are sometimes the ones nobody put in a contract, precisely because everyone who runs the system knows the business breaks without them.
Common misconceptions
- "Latency is about user experience." In bidding it's about existence — too slow and the bid doesn't happen at all.
- "Average latency is what matters." The tail matters; a budget you blow at top-of-hour costs you exactly when volume is highest.
- "A timeout is the same as a no-bid." Operationally they look alike, but a timeout discards a good decision — a pure, invisible loss.
- "Faster hardware solves it." Order-of-operations (cheap filters first, model last) and lean serving matter as much as raw speed.
- "ML can be a separate service call whenever." In-path inference must fit the budget; an unbounded round trip breaks it.
What good operation looks like
- Treat the latency budget as a hard wall, and design the funnel as an ordering of compute against it.
- Front-load cheap, decisive filters; defer expensive inference to the survivors.
- Watch the tail and the top-of-hour spikes, not just the average.
- When delivery drifts, rule out the clock before blaming targeting or pacing.
- Keep in-path ML lean — fast models, preloading, efficient protocols.
Open questions
- How should the budget be allocated across stages explicitly, and re-tuned as the funnel evolves?
- When is a heavier model worth its latency, and how do you decide per-request?
- Can predictive admission control drop doomed requests early to protect the budget for winnable ones?
A bid is a decision with a deadline, and the deadline is unforgiving: arrive late and you didn't bid at all. The sub-50ms budget is why the funnel is ordered the way it is, why inference runs last and lean, and why a perfectly configured campaign can still lose to the clock. Intelligence that doesn't fit inside the budget isn't intelligence the auction will ever see.