Blog
Pacing Is Not Division
Pacing a campaign isn't dividing a budget by the hours in a day. It's a real-time control problem over volatile supply. Here's how a production pacing controller keeps delivery on track — and what it does when supply collapses.
- Author
- Ad360 engineering
- Discipline
- Platform engineering
Ask how budget pacing works, and the common answer is some version of "divide the budget by the time remaining." Spend $24,000 over a day? That's $1,000 an hour. It is a clean mental model. It is also wrong in every way that matters.
The problem is that programmatic supply does not arrive on a schedule. The opportunities that match a campaign appear unevenly — by hour, by exchange, by audience availability, by sheer chance. A pacing system that assumed a tidy hourly quota would overspend when supply is rich and fall behind when it is scarce, ending the flight either early and expensively or late and short.
Pacing is not arithmetic. It is a control problem: continuously deciding whether to participate in this auction, right now, given everything observed so far, to keep cumulative delivery on its intended curve. This article describes how a real pacing controller does that — the one that runs as a discrete stage in the bidder's decisioning funnel, where "Pacing Cap" and "With Pacing Controller" appear as named gates.
Why pacing is a control problem
The constraints that make pacing hard are structural, not incidental:
- Supply is volatile. Match rates and impression rates fluctuate minute to minute.
- The bidder cannot manufacture impressions. It can only choose to bid, or not, on whatever shows up.
- The decision is per-request, made inside the bid's millisecond latency budget.
- The objective is to hit a delivery target — impressions, spend, or conversions — smoothly and on time, without dumping budget at the end.
So the controller's real job is to regulate the probability of participating in each eligible auction, so that cumulative delivery tracks the goal as supply rises and falls.
The mechanism
A line item carries a pacing goal — a daily impressions goal (CPM) or conversions goal (CPA), broken down upstream into hourly spend goals computed from time-series performance. The controller turns that goal into a moment-by-moment participation decision.
Its moving parts, drawn from the controller's own test coverage:
- Probabilistic gating. Each eligible auction is accepted with a probability; the controller raises or lowers that probability over time to steer delivery. Acceptance is validated against both real and controlled randomness.
- Submission rate, capped at 1.0. Participation can never exceed bidding on everything eligible.
- Two pacing modes — GREEDY and EVENLY.
- A trickle floor. A minimum participation level so a line item never goes fully dark — even when it is over its cap, or when goals are zero or invalid.
- Base-floor gating under under-delivery and cold start. When a line item is behind, or has just started with no history, participation is gated against a base floor.
- Cold-start protection and pacing memory. Smoothed estimates of submission rate, current acceptance probability, and a QPS estimate are carried in memory and updated with ALPHA-weighted (exponential) smoothing across calls, so the controller adapts without overreacting to noise.
GREEDY vs EVENLY
EVENLY spreads participation so that cumulative delivery follows the expected, roughly straight-line pace across the interval. It varies how often it bids precisely so that progress stays on the expected curve.
GREEDY captures delivery as early as conditions allow — but with guardrails. Its effective participation rate is capped (at 0.5 in the tested configuration, with a lower GREEDY floor around 25%), so "greedy" means front-loaded within limits, not all-in.
EVENLY follows the expected delivery curve; GREEDY front-loads delivery early, capped at a 0.5 effective rate with a ~25% floor. Both pursue the same goal — they differ in when they spend.
What this looks like in practice is visible in the simulation charts. Under moderately noisy but centered conditions (QPS ≈ 1,500; impression goal = 10,000), GREEDY reaches the full 10,000-impression goal by roughly minute 23 of the hour and then stops bidding for the rest of the interval. EVENLY tracks the expected diagonal almost exactly, arriving at the same goal near the end of the hour. Both hit the target; the difference is entirely in the shape of delivery.
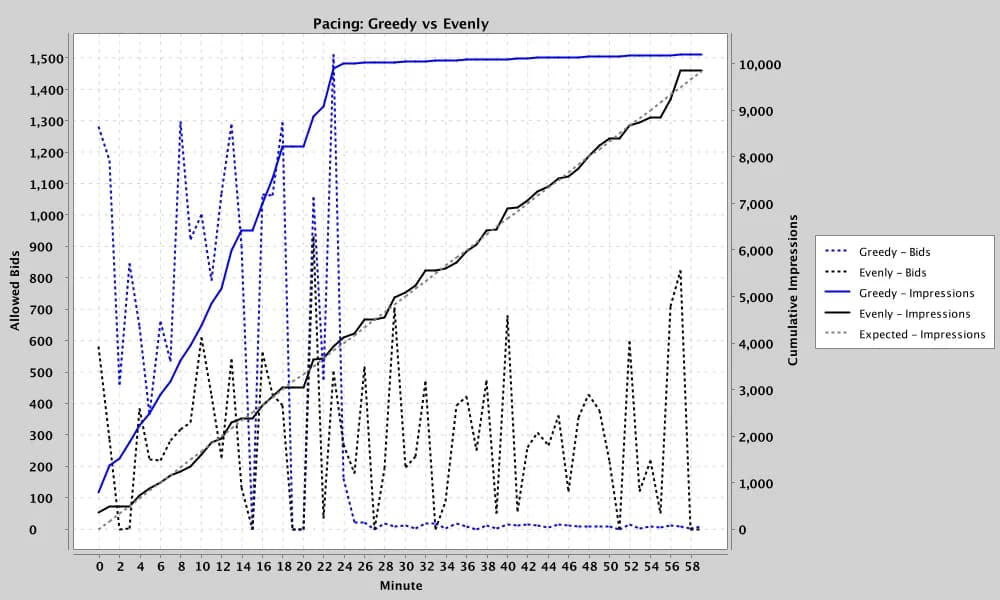
That difference is the decision. GREEDY suits situations where supply may dry up later, or where fast learning is worth paying for. EVENLY suits consistent all-day presence and smoother average prices. Each has a failure mode: GREEDY can exhaust budget before better supply appears; EVENLY can fall short if supply collapses late.
The hard cases: where naive pacing fails
A pacing system is only as good as its behavior when conditions misbehave. Two scenarios separate a real controller from a quota.
Recovering from under-delivery
When the first ~30 minutes of an hour deliver poorly — very low match and impression rates — both modes fall well below the expected delivery line. The question is whether the controller can recover once conditions improve. It does: as supply returns, participation ramps and cumulative delivery catches up to the goal by the end of the hour. Crucially, the catch-up is regulated by the same probabilistic gating that governs normal operation — not a reckless "spend whatever is left" dump. The system recovers; it does not panic.
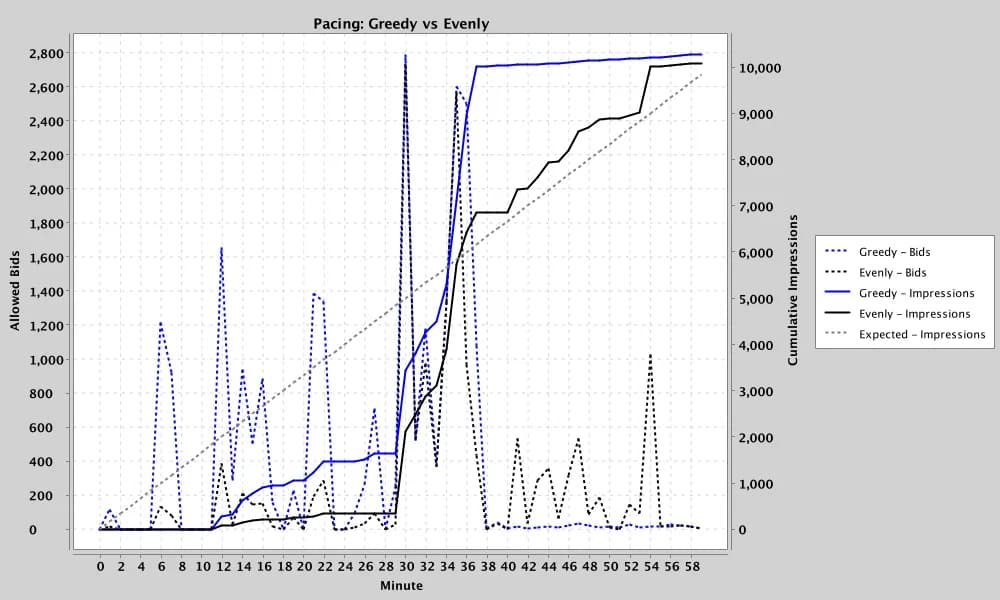
When supply simply isn't there
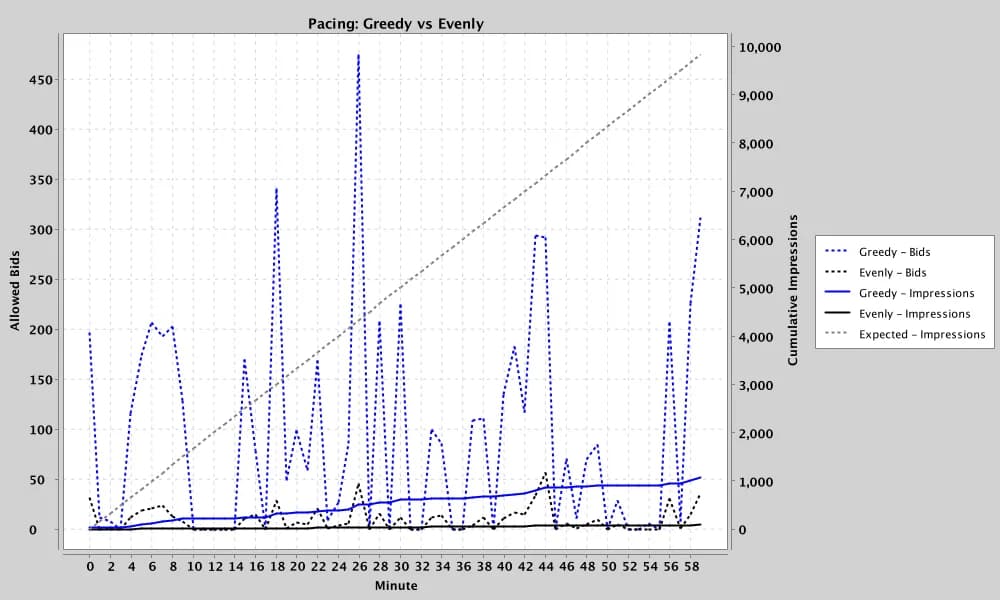
Now hold the match rate near 0.001 for an entire hour. The 10,000-impression goal is physically unreachable — the inventory does not exist. The correct behavior is not to thrash. Here the trickle floor keeps the line item minimally participating, accumulating a small fraction of the goal rather than either going completely dark or burning everything on the rare match that appears. Cold-start and fallback logic keep the line item alive and ready for the moment supply returns, and the shortfall is reported honestly rather than disguised. Failing gracefully under genuine scarcity is a feature; pretending to deliver would be a bug.
How it's tested (and why that matters)
What makes this credible is that the behavior is specified and simulated, not merely asserted. The testing happens in two layers.
Unit tests pin specific behaviors:
- Effective rate capped at 0.5 in GREEDY mode; submission rate capped at 1.0.
- Trickle floor applied when goals are zero or invalid.
- Base-floor gating under under-delivery and cold start.
- Pacing memory smoothing submission rate, acceptance probability, and QPS estimate across calls.
- Probabilistic acceptance validated with both ramping and randomized inputs; value clamping kept within bounds.
Integration/visualization tests then simulate full delivery pipelines (QPS ≈ 1,500–1,800; CPM ≈ 5–7; 10,000-impression goals) across a battery of conditions — moderate noise, multi-hour transitions with changing objectives, high match rates, fluctuating windows, chaotic oscillation, prolonged under-delivery, and persistently poor supply — each rendered as a GREEDY-vs-EVENLY chart comparing allowed bids and cumulative impressions against the expected curve.
This is precisely what most "pacing" claims cannot show: the behavior is defined in tests, exercised under stress, and visualized against an expected baseline.
Common misconceptions
- "Pacing equals budget divided by hours." It ignores supply volatility and guarantees over- or under-delivery.
- "Front-loading is always bad." GREEDY is the right call when supply is fragile or learning speed matters.
- "Even pacing means equal bids each hour." Even pacing means equal progress against the expected curve — achieved by varying participation as supply varies.
- "Under-delivery is a buying or targeting problem." Often it is a control problem — or an honest supply limit the controller should surface, not hide.
- "The controller should always spend the whole budget." When supply genuinely is not there, dumping is a defect, not diligence.
What good operation looks like
- Match the mode to the goal: even presence and branding favor EVENLY; fragile or time-limited supply and fast learning favor GREEDY.
- Read delivery against the expected curve, not against the clock.
- Treat a trickle-floored, under-delivering line item as a supply signal — investigate targeting, floors, and inventory rather than reflexively raising bids.
- Trust graceful recovery, and resist manual end-of-flight dumping.
Open questions
The discipline is not finished. Several questions remain genuinely open:
- How should pacing objectives adapt to curated or constrained supply, where the available pool is deliberately narrowed?
- Can the mode itself — greedy versus even, and the floor values — be learned per line item rather than configured?
- What delivery guarantees can be made jointly with outcome goals, pacing for both spend and performance rather than treating them separately?
Pacing is where a campaign's intent meets the messy reality of supply. Done as division, it breaks the moment reality stops cooperating. Done as control — probabilistic, memory-smoothed, floored, and tested against chaos — it keeps delivery honest whether supply is generous, volatile, or simply absent.